
课程介绍
本课程来自某课网,经百课优(baikeu.com)精心整理发布,是一套Python分布式爬虫课。数据时代已经来临,越来越多的工作使用数据,而爬虫正是快速获取数据最重要的方式,所以你懂的。本课程持续迭代三年、良心口碑,由浅入深,从0讲解爬虫基本原理,讲精讲透流行爬虫框架Scrapy,单机爬虫(Scrapy)到分布式爬虫(Scrapy-Redis)步步深入,开启你的爬虫工程师之路。





课程目录
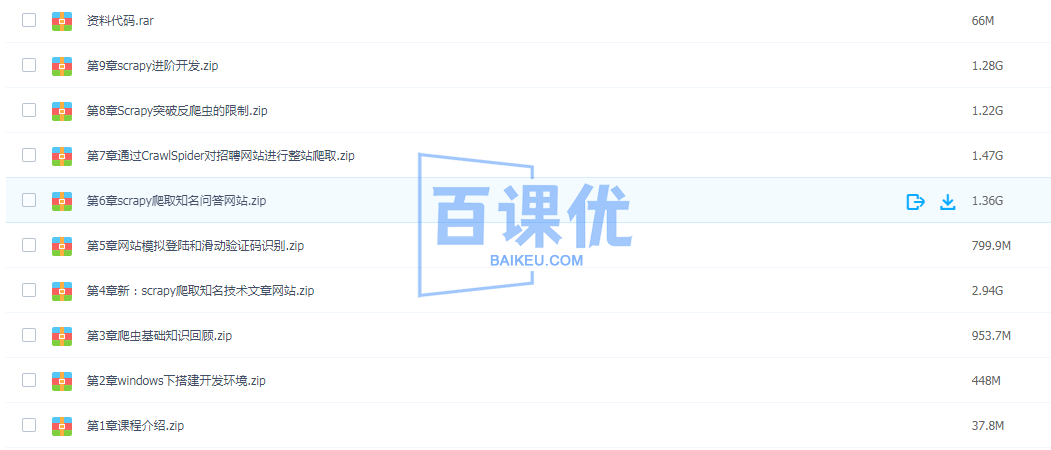
第1章 课程介绍
介绍课程目标、通过课程能学习到的内容、和系统开发前需要具备的知识
第2章 windows下搭建开发环境
介绍项目开发需要安装的开发软件、 python虚拟virtualenv和 virtualenvwrapper的安装和使用、 最后介绍pycharm和navicat的简单使用
第3章 爬虫基础知识回顾
介绍爬虫开发中需要用到的基础知识包括爬虫能做什么,正则表达式,深度优先和广度优先的算法及实现、爬虫url去重的策略、彻底弄清楚unicode和utf8编码的区别和应用。
第4章 新: scrapy爬取知名技术文章网站
搭建scrapy的开发环境,本章介绍scrapy的常用命令以及工程目录结构分析,本章中也会详细的讲解xpath和css选择器的使用。然后通过scrapy提供的spider完成所有文章的爬取。然后详细讲解item以及item loader方式完成具体字段的提取后使用scrapy提供的pipeline分别将数据保存到json文件以及mysql数据库中。
第5章 网站模拟登陆和滑动验证码识别
本章节我们将解决两个问题:1. 防止selenium被网站识别出来 2. 滑动验证码识别,滑动验证码识别我们将采用opencv识别和机器学习平台识别。 滑动验证码作为当前最流行的验证码,识别滑动验证码将使得我们能解决绝大部分网站的模拟登陆…
第6章 scrapy爬取知名问答网站
通过上一章节的学习,本章节我们将对具体的网站进行需求分析、表结构设计等、本章详细的分析了网站的网络请求并分别分析出了网站问题回答的api请求接口并将数据提取出来后保存到mysql中
第7章 通过CrawlSpider对招聘网站进行整站爬取
本章完成招聘网站职位的数据表结构设计,并通过link extractor和rule的形式并配置CrawlSpider完成招聘网站所有职位的爬取,本章也会从源码的角度来分析CrawlSpider让大家对CrawlSpider有深入的理解。
第8章 Scrapy突破反爬虫的限制
本章会从爬虫和反爬虫的斗争过程开始讲解,然后讲解scrapy的原理,然后通过随机切换user-agent和设置scrapy的ip代理的方式完成突破反爬虫的各种限制。本章也会详细介绍httpresponse和httprequest来详细的分析scrapy的功能,最后会通过云打码平台来完成在线验证码识别以及禁用cookie和访问频率来降低爬虫被屏蔽的可能性。…
第9章 scrapy进阶开发
本章将讲解scrapy的更多高级特性,这些高级特性包括通过selenium和phantomjs实现动态网站数据的爬取以及将这二者集成到scrapy中、scrapy信号、自定义中间件、暂停和启动scrapy爬虫、scrapy的核心api、scrapy的telnet、scrapy的web service和scrapy的log配置和email发送等。 这些特性使得我们不仅只是可以通过scrapy来完成…
第10章 scrapy-redis分布式爬虫
Scrapy-redis分布式爬虫的使用以及scrapy-redis的分布式爬虫的源码分析, 让大家可以根据自己的需求来修改源码以满足自己的需求。最后也会讲解如何将bloomfilter集成到scrapy-redis中。
第11章 cookie池系统设计和实现
为了让爬取代码和解析代码不会受到模拟登录的影响,将模拟登录独立成独立的服务变得很重要,cookie池就是为了解决这类问题而生,多账号登录管理、如何让网站接入变得容易都会是cookie池需要解决的问题。本章节就重点解决cookie池设计和开发的细节问题。 …
第12章 各种验证码的识别
滑动验证码变得越来越流行,如何解决滑动验证码就成为了模拟登录中重要的一个环节,本章节聚焦解决滑动验证码的各种细节问题。
第13章 增量抓取
增量抓取和数据更新是爬虫运行中经常遇到的问题,比如当前爬虫正在运行,但是新增的数据如何及时发现,如何将后来的url先进行抓取,如何发现新数据都是实际开发中经常原道的问题,本章节通过修改scrapy-redis的源码以最小的代价来解决上诉问题,通过本章节的学习我们将会更加懂得如何去控制爬虫的运行环节。…
第14章 elasticsearch搜索引擎的使用
本章将讲解elasticsearch的安装和使用,将讲解elasticsearch的基本概念的介绍以及api的使用。本章也会讲解搜索引擎的原理并讲解elasticsearch-dsl的使用,最后讲解如何通过scrapy的pipeline将数据保存到elasticsearch中。
第15章 django搭建搜索网站
本章讲解如何通过django快速搭建搜索网站, 本章也会讲解如何完成django与elasticsearch的搜索查询交互。
第16章 scrapyd部署scrapy爬虫
本章主要通过scrapyd完成对scrapy爬虫的线上部署。
第17章 课程总结
重新梳理一遍系统开发的整个过程, 让同学对系统和开发过程有一个更加直观的理解。
学员评价
喵耳朵儿 好评
我觉得这个爬虫课程真的很不错。虽然我本身已经有了一些爬虫的基础,但是在听了这个课之后还是有了很多的收获。首先是工具的使用,老师在环境搭建课程中介绍的virtualenvwrapper这个工具我就之前没用过,python2和3之间的切换等等一直是比较头疼的问题。之后就是scrapy的具体使用。老师先从简单的demo实现,然后逐级封装,最后变成一个高可用的框架。所谓授之以鱼不如授之以渔,老师期间也不忘介绍网站工作的各种原理。 唯一的不足就是,,,这门课和《Python高效编程技巧实战》组合起来是有优惠的,我买的时候并没有看到。。。orz,想买的同学一定要看看有没有心动的组合套餐!
资源截图

1、本站信息来自网络,版权争议与本站无关
2、本站所有主题由该帖子作者发表,该帖子作者与本站享有帖子相关版权
3、其他单位或个人使用、转载或引用本文时必须同时征得该帖子作者和本站的同意
4、本帖部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责
5、用户所发布的一切软件的解密分析文章仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。
6、您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容。
7、请支持正版软件、得到更好的正版服务。







